
Programming with Python
Handling topographic data
Learning Objectives
- Explain what a library is, and what libraries are used for
- Load a Python library and use the tools it contains
- Read data from a file into a program
- Assign values to variables
- Extract values and slices of data
- Perform operations on arrays of data
- Display simple graphs
The best way to learn how to program is to do something useful and interesting, so this introduction to Python is built around a task that is particularly relevant to the CSDMS community: building numerical models.
Python is an increasingly popular programming language. It’s good as a first language because it is concise and easy to read, but it is also a great language for more experienced programmers to learn because it is powerful and versitile. While a lot of basic functionality is built directly into a language like Python, a massive collection of tools for every imaginable task exist in libraries (also called packages).
The most common libraries for scientific programming come bundled with the Anaconda distribution of Python that we are using in this workshop. Check out the Python Package Index to see what else is available.
Loading data
The goal of this Python workshop is to build a two-dimensional diffusion model of landscape evolution. The first step is to load an elevation dataset (the initial conditions for our model) and figure out how to manipulate it.
Take a look at the contents of the file data/topo.asc. For simplicity, we are not using a real ASC file for this tutorial. We’ve removed the header and the projection file to leave only the rectangular array of elevation values and we replaced the commas between values with spaces.
In order to load the elevation data, we need to import a library called Numpy. You use this library to do fancy things with numbers (ie. math), especially when we are handling matrices or arrays. We can load Numpy with the command import:
import numpyWithin the Jupyter (iPython) notebook, pressing Shift+Enter runs the commands in the selected cell. Importing a library should not produce visible output.
Importing a library is like pulling a toolbox out of a storage locker and placing it on your workbench. Python has a set of built-in functions that are always available (the everyday tools on your workbench). Libraries provide additional functionality to Python (the specialized tools in the toolbox that you only sometimes need).
Once we’ve loaded the library, we can use a function in this library to read the data file:
numpy.loadtxt('data/topo.asc')array([[ 3198.8391, 3198.123 , 3197.1584, ..., 2583.3293, 2585.4368,
2589.1079],
[ 3198.3306, 3197.5242, 3196.4102, ..., 2582.6992, 2584.9167,
2587.801 ],
[ 3197.9968, 3196.9197, 3195.7188, ..., 2581.8328, 2583.8159,
2586.0325],
...,
[ 3325.1509, 3334.7822, 3343.3154, ..., 2780.8191, 2769.3235,
2762.373 ],
[ 3325.0823, 3335.0308, 3345.4963, ..., 2775.3345, 2765.7131,
2759.6555],
[ 3326.6824, 3336.5305, 3348.1343, ..., 2769.7661, 2762.5242,
2756.6877]])The expression numpy.loadtxt(...) tells Python to run the function loadtxt from the numpy library. This dotted notation, with the syntax thing.component, is used everywhere in Python to refer to parts of things.
The function call numpy.loadtxt has one parameter: the name of the file we want to read. The filename is a character string (or simply string) so it is in quotes.
Because we haven’t told iPython where to put the output of numpy.loadtxt, the Notebook just displays it on the screen. The output is the data we just loaded. By default, only a few rows and columns are shown (with ... to omit elements when displaying big arrays).
Our call to numpy.loadtxt read the file but didn’t save the values. In order to save the data and be able to access it later, we need to assign the values to a variable. A variable name is just a label that refers to an object in the memory. We can assign a variable name to an object using =. Python’s variables must begin with a letter and are case sensitive.
Let’s re-run numpy.loadtxt and assign the output to a variable name:
topo = numpy.loadtxt('data/topo.asc')This command doesn’t produce any visible output. If we want to see the data, we can print the variable’s value with the command print:
print topo[[ 3198.8391 3198.123 3197.1584 ..., 2583.3293 2585.4368 2589.1079]
[ 3198.3306 3197.5242 3196.4102 ..., 2582.6992 2584.9167 2587.801 ]
[ 3197.9968 3196.9197 3195.7188 ..., 2581.8328 2583.8159 2586.0325]
...,
[ 3325.1509 3334.7822 3343.3154 ..., 2780.8191 2769.3235 2762.373 ]
[ 3325.0823 3335.0308 3345.4963 ..., 2775.3345 2765.7131 2759.6555]
[ 3326.6824 3336.5305 3348.1343 ..., 2769.7661 2762.5242 2756.6877]]Defining variables
Track how variable names and objects are connected after each statement in the following program. What are the values of the variables after running each line of code?
mass = 47.5
age = 122
mass = mass * 2.0
age = age - 20Solution
| Line number | mass |
age |
|---|---|---|
| 1 | 47.5 | doesn’t exist |
| 2 | 47.5 | 122 |
| 3 | 95.0 | 122 |
| 4 | 95.0 | 102 |
Tracking variables
What does the following program print?
Bonus: Who was Grace Hopper?
first, second = 'Grace', 'Hopper'
third, fourth = second, first
print third, fourthAssignment statement
Why doesn’t this work?
17 = nSolution
The assignment token, ‘=’, should not be confused with the equals sign, in the mathematical sense. The assignment statement binds a name, on the left-hand side of the operator, to a value, on the right-hand side. When reading or writing code, say to yourself “n is assigned 17” or “n gets the value 17”. Don’t say “n equals 17”.
Also, variable names must start with a letter or an underscore so the number 17 could not be used as a variable name.
The correct way to assign the value 17 to the variable name n is this:
n = 17Using its variable name, we can see that type of object the variable name topo is assigned to. The function type tells us that the variable name topo points to an N-dimensional array created by the Numpy library:
type(topo)numpy.ndarrayWe can also get the shape of the array:
print topo.shape(500, 500)The array has 500 rows and 500 columns. The file we imported contains elevation data (in meters, 2 meter x 2 meter cells) for an area along the Front Range of Colorado, just south of Boulder. The area that this array covers is 1 km x 1 km.
The object of type numpy.ndarray that the variable topo is assigned to contains the values of the array as well as some extra information about the array. These are the members or attributes of the object, and they describe the data in the same way an adjective describes a noun. The command topo.shape calls the shape attribute of the object topo, which contains its dimensions. We use the same dotted notation for the attributes of objects that we use to call functions inside libraries because they have the same part-and-whole relationship.
Plotting
Rasters are just big two dimensional arrays of values. In the case of DEMs, those values are elevations. It’s very hard to get a good sense of what a landscape looks like by looking directly at a giant array of numbers. This information is better conveyed through plots and graphics.
Data visualization deserves an entire lecture (or course) of its own but we can explore a few features of Python’s matplotlib library here. While there is no “official” plotting library in Python, this package is the de facto standard.
We start by importing the pyplot module from the library matplotlib. Since we don’t need all of the tools available in matplotlib, we use the dotted notation to specify the particular collection we want.
import matplotlib.pyplotWe can use the function imshow (“image show”) within matplotlib.pyplot to display an array as a 2D image:
matplotlib.pyplot.imshow(topo)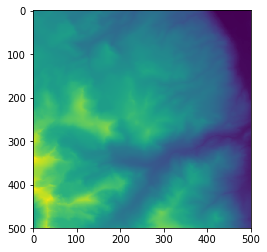
Indexing
We can access an individual value in an array by referencing its position. We specify the location of the value using an integer index in square brackets:
print 'elevation at the NW corner of topo:', topo[0,0], 'meters'elevation at the NW corner of topo: 3198.8391 metersprint 'elevation at an arbitrary point in topo:', topo[137,65], 'meters'elevation at an arbitrary point in topo: 3251.1179 metersWhen accessing values in a two dimensional array, the indices are ordered [row,column]. The expression topo[137, 65] should not surprise you too much but topo[0,0] might.
Programming languages like Fortran and MATLAB start counting at 1 because that’s what (most) humans have done for thousands of years. Languages in the C family (including C++, Java, Perl, and Python) count from 0 because it’s simpler for computers to do. So if we have an M×N array in Python, the indices go from 0 to M-1 on the first axis (rows) and 0 to N-1 on the second (columns). In MATLAB, the same array (or matrix) would have indices that go from 1 to M and 1 to N. Zero-based indexing takes a bit of getting used to. One way to remember the rule is that the index is how many steps we have to take from the start to get to the item we want.
Python also allows for negative indices to refer to the position of elements with respect to the end of each axis. An index of -1 refers to the last item in a sequence, -2 to the second to last, and so on. Since index [0,0] is the upper left corner of an array, index [-1,-1] is the lower right corner of the array:
print topo[-1,-1]2756.6877Slicing
The statement topo[0,0] selects a single element in the array topo. We can also use integer indices to slice sections of the array with multiple values. For example, we can select a small square on the top left corner of the array like this:
print topo[0:5, 0:5][[ 3198.8391 3198.123 3197.1584 3196.2017 3193.8813]
[ 3198.3306 3197.5242 3196.4102 3194.7559 3191.9763]
[ 3197.9968 3196.9197 3195.7188 3193.3855 3190.5371]
[ 3198.054 3196.7031 3194.9573 3192.4451 3189.5288]
[ 3198.3289 3196.9111 3195.335 3192.7874 3190.0085]]
The slice [0:5,0:5] means “For both the rows and columns, start at index 0 and go along the axis up to, but not including, index 5”.
We don’t need to include the upper or lower bound of the slice if we want to go all the way to the edge. If we don’t include the lower bound, Python uses 0 by default. If we don’t include the upper bound, the slice runs to the end of the axis:
print topo[:5, 497:][[ 2583.3293 2585.4368 2589.1079]
[ 2582.6992 2584.9167 2587.801 ]
[ 2581.8328 2583.8159 2586.0325]
[ 2580.9688 2582.8279 2584.7751]
[ 2580.2957 2582.1313 2584.1919]]If we don’t include either the lower or upper bound of a slice (i.e., if we just use the colon), the slice includes every value along that axis:
print topo[0:2,:].shape(2, 500)Elevation values
Use indexing to answer the following questions. Check your answers against the visualization of the array:
- Is the NW corner of the region higher than the SW corner? What’s the elevation difference?
- What’s the elevation difference between the NE corner and the SE corner?
- What’s the elevation at the center of the region shown in the array? (Hint: You can use the function
len())
Solution
print 'NW corner:', topo[0,0], 'meters'
print 'SW corner:', topo[-1,0], 'meters'
print 'Difference between NW and SW corners:', topo[0,0] - topo[-1,0], 'meters'
print '-' * 60
print 'Difference between NE and SE corners:', topo[0,-1] - topo[-1,-1], 'meters'
print '-' * 60
print 'Elevation at the center:', topo[len(topo)/2, len(topo)/2], 'meters'NW corner: 3198.8391 meters
SW corner: 3326.6824 meters
Difference between NW and SW corners: -127.8433 meters
------------------------------------------------------------
Difference between NE and SE corners: -167.5798 meters
------------------------------------------------------------
Elevation at the center: 3372.386 metersSlicing strings
Indexing and slicing work the same way for any type of sequence, including Numpy arrays, lists, and strings:
element = 'oxygen'
print 'first three characters:', element[0:3]
print 'last three characters:', element[3:6]first three characters: oxy
last three characters: gen- What is the value of
element[:4]? What aboutelement[4:]? Orelement[:]?
Solution
print 'element[:4]:', element[:4]
print 'element[4:]:', element[4:]
print 'element[:]:', element[:]element[:4]: oxyg
element[4:]: en
element[:]: oxygen- What is
element[-1]? What iselement[-2]?
Solution
print 'element[-1]:', element[-1]
print 'element[-2]:', element[-2]element[-1]: n
element[-2]: e- Given those answers, explain what
element[1:-1]does.
Solution
Creates a substring from index 1 up to (but not including) the last value, effectively removing the first and last letters from ‘oxygen’.
Empty slices
The expression element[3:3] produces an empty string, i.e., a string that contains no characters. If topo holds our array of elevation data, what does topo[3:3,4:4] produce? What about topo[3:3,:]?
Solution
print 'topo[3:3,4:4]:', topo[3:3,4:4]
print 'topo[3:3,:]:', topo[3:3,:]topo[3:3,4:4]: []
topo[3:3,:]: []Concatenating strings
Create a new variable named text and assign to it the string “The quick brown fox jumped over the lazy dog.” (note the capitalization and punctuation; include the quotes so Python recognizes it as a string).
Use slicing and the print statement to extract and combine pieces of text to produce these sentences (again, note capitalization and punctuation!):
- the lazy dog.
- fox jumped over dog
- The lazy fox jumped over the quick brown dog.
Hints:
- You can use the plus sign (+) to concatenate strings. Try it by running
print "lazy" + "dog". - Remember that you can use negative indices!
- It’s easiest to do this by trial and error. Guess at the bounds of the slice needed to extract the word you want and then adjust.
Solution
text = "The quick brown fox jumped over the lazy dog."
print text[-13:]
print text[16:32] + text[-4:-1]
print text[:3] + text[-10:-4] + text[16:36] + text[4:16] + text[-4:]the lazy dog.
fox jumped over dog
The lazy fox jumped over the quick brown dog.Displaying slices
Use the function imshow from matplotlib.pyplot to make one figure showing the elevations of the northern half of the region and another plot showing the elevations of the southern half. You’ll need to use separate cells in the Jupyter Notebook for each plot.
Solution
# northern half
matplotlib.pyplot.imshow(topo[:len(topo)/2,:])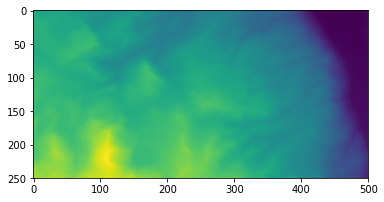
# southern half
matplotlib.pyplot.imshow(topo[len(topo)/2:,:])
Finding the center (Advanced)
We can get the elevation of the centerpoint of the array topo using these indices: topo[len(topo)/2,len(topo)/2]. The function len() gives the length of the longest axis of the array, so this wouldn’t work if the array were not square (if it had a different number of rows and columns).
Take a (small) slice of the array
topoand assign it to a new variable calledt. The height of the new arraytshould be greater than the width and both the height and the width should be even numbers (6 x 4 is a good size).Use indexing to extract the value of the centerpoint of the new array
t. Write the indices using variables, not numbers (ie. don’t writet[3,2])
Hint: The method topo.shape gives the number of rows and columns in topo. Knowing this, get the shape of t and assign it to a variable. Use indexing on that variable to get the number of rows (index 0) and the number of columns (index 1) in t.
Solution
t = topo[:6,:4]
height_width = t.shape
print 'Shape of t:', height_width
num_rows = height_width[0]
num_cols = height_width[1]
print 'Value at centerpoint:', t[num_rows/2, num_cols/2], 'meters'Shape of t: (6, 4)
Value at centerpoint: 3194.9573 meters- Make a rough sketch of array
t. Identify the cell that you identified as the centerpoint usingt.shape. Are you really pointing to the center of your array? How far off is it?
Solution
The centerpoint of an array with an even number of rows and columns should fall at the intersection of four cells. Using half the height and width as indices places us half a cell off.
Non-continuous slices
So far we’ve seen how to use slicing to take single blocks of successive entries from a sequence. But what if we want to take a subset of entries that aren’t next to each other in the sequence?
You do this by providing a third argument - the step size - to the index range within the brackets. The example below shows how you can take every third entry in a list:
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[0:12:3]
print "Every third prime:", subsetEvery third prime: [2, 7, 17, 29]Notice that the slice taken begins with the first entry in the range, followed by entries taken at equally-spaced intervals (the steps) thereafter. If you wanted to begin the subset with the third entry, you would need to specify that as the starting point of the sliced range:
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[2:12:3]
print "Every third prime:", subsetEvery third prime: [5, 13, 23, 37]Garbled quotes
Use the step size argument to create a new string that contains only every other character in the string “Your Mother was a Hamster, and your Father smelt of Elderberries!”.
Solution
text = "Your Mother was a Hamster, and your Father smelt of Elderberries!"
print text[::2]Yu ohrwsaHmtr n orFte ml fEdrere!Garbled quotes, part 2 (Advanced)
Repeat the challenge above but, this time, create a new string that contains only every other character, starting from the end of the string and moving left.
Hint: Remember negative indices.
Solution
text = "Your Mother was a Hamster, and your Father smelt of Elderberries!"
print text[-1:-len(text)-1:-2]!ererdEf lm etFro n rtmHaswrho uY